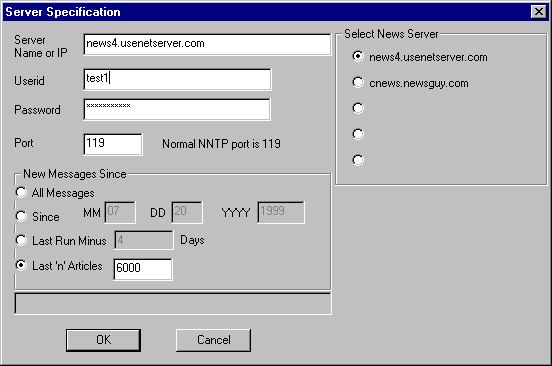
The Server Info Dialog is used to specify the connection information
used to get to the news server. This will always include the
name of the server and may include a login and password. The
default port 119 is almost always used.
The objects on the Server Info dialog are as follows:
The name of the News server machine, either as a name or as an IP address. For example: www.cit-news.com, accessive.at.remarq.com/corporate/usenetfes.html, or 192.1.2,3
This is the userid used to authenticate to the news server. If the news server does not require you to log on, this field can be left blank.
NNTP servers seem to have 2 ways of validating users. They may use one or both of these methods.
This is the password used to authenticate to the news server. It is saved between sessions. In general, it will be required if a login is required.
The NNTP (Network News Transfer Protocol) port is normally 119. If you have access to a news server which uses some other port, you can change this information here.
This button closes the dialog, returning to the main dialog. The updated data is saved at this time in the ZUB.ini file. Note that the news server displayed is the one which will be used in the next download run.
This button closes the dialog, returning to the main dialog.
Any changes made are discarded. The ![[X] button](X.jpg) "" in the upper right
corner has the same effect.
"" in the upper right
corner has the same effect.
Zub will remember the server name, userid, password, and port for up to five different news servers. To add a new server, click one of the blank entries, fill in the server, userid, password, and port data and click OK. Whichever button is selected when the dialog is closed is the currently active news server.
The Radio buttons in this group control how many news article headers are read from each group. The more read the more files will be seen as available for download. The more read, the longer it takes. So there is the tradeoff. The choices are as follows.
If All Messages is checked, all available article headers for the newsgroup will be read the next time the run button is pressed from the main dialog window. If Caching is enabled, some of the headers may not have to be read as they are already available locally.
The headers will be searched in a binary fashion to find the oldest article from the specified date. All articles from that point newer will be read.
The date last time Zub was run minus the specified number of days will be calculated and the headers will be retrieved from that point. Since this is not done on a group by group basis, it is not that interesting an option. It may be removed in future releases.
The newest 'n' articles will be retrieved the next time a run is made where 'n' is the number specified in the dialog box. The behavior of this option is modified noticeably by caching. If caching is off or the cache for this newsgroup is empty, the newest 'n' articles are read - plain and simple.
If caching is on, the cache and what headers are cached comes into play. The following examples give a feel for what is going on: